Downtime Isn’t Everything… Slowdowns Are the Hidden Killer of Throughput
 Walk into almost any operation and ask how they track performance, and you’ll get a familiar answer.
Walk into almost any operation and ask how they track performance, and you’ll get a familiar answer.
Downtime.
It’s tracked on paper, in Excel, or in dedicated systems. It’s reviewed in daily meetings. It’s categorized, Pareto’d, and debated.
And that makes sense. When production stops, it’s visible. It’s urgent. It demands attention.
But here’s the problem.
In many operations, downtime is where the conversation starts… and ends.
Meanwhile, one of the biggest drivers of lost production quietly slips through the cracks:
Slowdowns.
The Blind Spot in Most Operations
Most teams do look at production rates, at least at a high level.
Average throughput might get reviewed weekly or monthly. There may even be targets or benchmarks tied to design capacity.
But very few operations consistently identify and track individual slowdown events.
Not just “we ran at 85% this week,” but:
- When did the rate drop?
- How long did it last?
- What caused it?
- Was it avoidable?
Without that level of visibility, slowdown losses stay aggregated, abstract, and ultimately… ignored.
Why Slowdowns Are So Hard to Track
This isn’t a capability gap as much as it is a complexity problem.
Tracking slowdown losses in real time is fundamentally harder than tracking downtime. It:
- Requires more effort from operators and technicians
- Forces teams to define what actually qualifies as a slowdown
- Gets messy in processes that are inherently variable
- Demands a clear distinction between planned and unplanned rate loss
Even something as simple as setting a “normal” production rate can become a debate.
Is it nameplate capacity? Last month’s average? Best-ever performance?
Because of this ambiguity, many teams avoid the problem altogether.
And That’s Exactly Why They’re Dangerous
Downtime gets attention because it’s binary. You’re either running or you’re not.
Slowdowns, on the other hand, are easy to normalize.
A slightly lower rate becomes “just how this line runs.”
A temporary constraint becomes a permanent assumption.
A workaround becomes standard operating practice.
No alarms. No escalation. No urgency.
Just a quiet erosion of throughput.
But the math tells a different story.
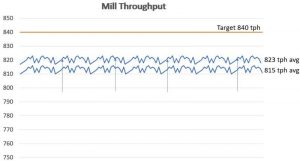
Running 15% below your potential for a full week can be equivalent to losing an entire day of production.
The difference?
No one ever logs it as a “problem.”
Where Slowdown Losses Really Come From
When you start digging into slowdown events, patterns emerge quickly.
They’re rarely caused by a single dramatic failure. Instead, they tend to come from systemic, often accepted conditions:
- Operating philosophies and “how we usually run”
- Mechanical or control limitations that never quite trigger a stop
- Product sequencing and changeover decisions
- Equipment degradation that chips away at performance over time
- Operators settling into low-risk, comfortable operating modes
Individually, each of these might seem minor.
Collectively, they can represent a massive amount of lost capacity.
And none of them show up clearly if all you track is downtime.
The Opportunity: Unlocking Hidden Capacity
This is where the real upside lies.
From a production loss perspective, slowdowns are often a treasure trove of hidden capacity.
Unlike major downtime events, which may require capital investment or significant intervention, many slowdown drivers are:
- Operational
- Behavioral
- Procedural
In other words, they’re fixable.
But only if you can see them.
Identifying and quantifying slowdown losses is the first step to:
- Exposing what is truly constraining production
- Focusing Continuous Improvement efforts on the highest-impact issues
- Aligning teams around what “good” actually looks like
- Pushing production closer to design capacity… without adding new equipment
Shifting the Mindset
Improving throughput isn’t just about eliminating failures.
It’s about challenging what has quietly become acceptable.
That starts with treating slowdowns with the same level of discipline as downtime:
- Define them clearly
- Track them consistently
- Investigate them rigorously
When you do, what once felt like “normal operation” starts to look a lot more like opportunity.
Final Thought
Downtime is obvious.
Slowdowns are persistent.
And in many operations, persistent losses do far more damage than the failures everyone can see.
The question isn’t whether slowdowns are costing you production.
It’s whether you’ve made them visible enough to do something about it.
